基于多任务生成对抗网络的高光谱图像分类方法研究
汤云贺
(苏州空天信息研究院, 苏州 215124)
摘要: 高光谱图像分类作为实现高光谱遥感图像众多应用的先决条件, 一直是遥感领域的研究热点与难点。近些年, 各种深度学习网络模型方兴未艾并逐步应用于高光谱图像分类领域, 但是高光谱图像数据集往往存在着标记样本稀少、类别分布不均的问题, 导致网络在训练样本有限时容易出现过拟合现象, 取得较低的分类精度。为了解决以上问题, 本文深入调研了生成对抗网络并对其进行了改进, 同时与多任务学习结合, 提出了基于多任务生成对抗网络的高光谱图像分类方法, 通过有效训练生成器和判别器实现对于高光谱数据特征的深度挖掘, 其中生成器生成大量的虚拟样本以扩充训练集, 判别器依靠输入源判别任务、度量任务和地物分类任务的信息交互实现分类性能的提升; 所提出的方法在两个标准数据集上验证了各模块设计的有效性, 并证明该方法能够依靠样本扩充以及多任务学习架构表现出相对优异的分类性能, 并且对训练样本的数量表现出较低的依赖性。
关键词: 高光谱图像分类, 生成对抗网络, 多任务学习, 样本扩充
DOI: 10.48014/ais.20250313001
引用格式: 汤云贺. 基于多任务生成对抗网络的高光谱图像分类方法研究[J]. 交叉科学学报, 2025, 2(1): 37-47.
文章类型: 研究性论文
收稿日期: 2025-03-13
接收日期: 2025-03-19
出版日期: 2025-03-28
1 引言
高光谱遥感能够同时捕捉场景中的光谱以及空间特征,是重要的对地观测技术手段,因此被广泛应用于城市规划[1]、农业监测[2]、矿产勘查[3]、军事侦察[4]等领域。高光谱遥感应用的广泛实现依赖于高效的高光谱图像分类技术,其目的是为了确定高光谱影像中每个像素的类别。随着遥感技术的快速发展,高光谱遥感可以以大约10纳米的光谱分辨率在可见光到近红外的波段范围内获取几十甚至上百幅影像,提供了丰富而细致的光谱信息。然而,高光谱图像的高维性、海量性、信息冗余性也为高光谱图像分类带来了挑战。
多种源自机器学习领域的分类算法已被应用于高光谱图像分类,常用的方法有随机森林(Random Forest,RF)[5]、支持向量机(Support Vector Machines,SVMs)[6]等。然而,这些算法的特征提取过程和分类器设计过程是独立进行的,导致所提取的特征可能不是分类器所需要的最优特征,从而降低了分类精度。
与上述的传统机器学习模型相比,深度学习能够在提取高阶非线性特征的同时完成分类器的训练,组成一个统一的端到端的框架,并以数据驱动的方式进行优化。因此,近年来深度学习成为高光谱图像分类的强力手段。Hu等[7]首次设计了一个五层的卷积神经网络(Convolutional Neural Network,CNN),以每个像素的光谱作为输入,进行光谱特征的提取和分类。Li等[8]提出了一种基于像素对的投票策略,使一维卷积神经网络(1D-CNN)在标记样本较少时取得了可信的分类效果。文献[9]设计了一种创新的文本-光谱联合学习策略,将文本模态作为图像模态的补充,实现跨模态的知识迁移,取得了令人满意的分类成效。文献[10]验证了1D-CNN、2D-CNN、3D-CNN以及ResNet34四种方法在不同数据集上的性能,实验表明3D-CNN以及ResNet34对于处理具有复杂空间特征的高光谱数据集更有优势。虽然,CNN主导的方法已经在高光谱图像分类领域内展现出卓越的性能,但是当标记数据有限时,用少量数据训练大量的可学习参数易出现过拟合问题[11]。而在遥感领域,收集数据是昂贵而耗时的,而且收集到的数据存在类别分布不均、数量呈长尾分布的问题,致使网络权重向样本数量多的类别偏移,导致分类结果不佳。
综上所述,本文提出了基于光谱度量和多类判别的多任务生成对抗网络(Multi-task Generative Adversarial Networks,MTGAN)。网络中的生成器生成虚拟光谱曲线,以扩充训练样本,减轻网络对于标记样本的依赖。网络中的判别器提取数据特征并根据特征进行真假判别以及地物分类。同时,该判别器采用了一种多类对抗策略,以更好完成多分类任务上的对抗训练。此外,为了防止生成器对尚未充分训练的判别器产生过拟合,本文为生成器引入了度量任务。该网络通过输入源判别任务、度量任务和地物分类任务的信息交互实现分类性能的提升,在两个标准高光谱数据集上实施的实验充分验证了该方法的可行性和有效性。
2 MTGAN的框架及其实施流程
2.1 MTGAN总体概述
图1详细展示了MTGAN的架构,该网络架构主要由两个核心模块构成:生成器G与判别器D。生成器G的输入包含噪声向量及类别标签,其核心功能在于学习并模拟真实图像的光谱特征分布,进而生成逼真的虚拟光谱曲线。此外,生成器融入了自注意力机制模块,以更好地捕捉光谱带之间的长程依赖关系,提高生成样本的质量。判别器的输入涵盖真实样本以及由生成器产生的模拟样本,其功能是提取真实或虚拟样本的光谱特征,并针对得到的特征向量进行真假判别以及地物分类。判别器通过输入源判别以及地物分类任务进行协同训练,提升其在各任务上的表现能力。此外,生成器生成的虚拟样本扩充了判别器分类任务的训练集,这在一定程度上缓解了类别不平衡的问题,促使其学习到更优的特征表示,并减少了过拟合的风险。
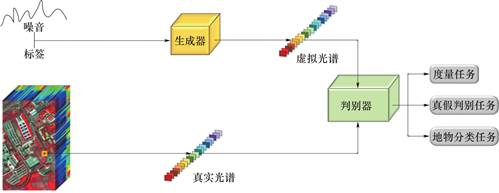
图1 MTGAN网络框架示意图
Fig.1 Schematic diagram of MTGAN network framework
2.2 自注意力模块
传统的卷积神经网络受限于卷积核尺寸,导致感受野有限,通常需要多层堆叠才能覆盖整个特征图,这可能限制了模型在处理长距离、多层次依赖关系上的能力。相比之下,自注意机制利用特征图内部的自相关性生成注意力权重[12],仅通过简单的查询与键值匹配即可捕获特征图的全局信息。鉴于高光谱图像包含丰富的光谱波段,相较于其他图像类型,模型在捕捉这些波段间长距离依赖关系时面临更大挑战。因此,模型需要引入自注意力机制,旨在计算光谱序列中各波段对特定目标波段的响应,从而提升模型性能,具体框架见图2。
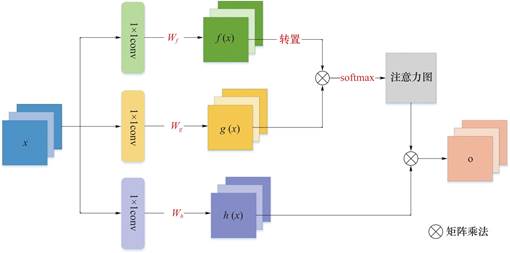
图2 自注意力机制框架示意图
Fig.2 Schematic diagram of mechanism framework of self-attention
具体计算过程如下:
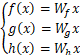 (1)
(1)
式中,x为输入的特征图;Wf、Wg、Wh为大小为1×1的卷积核的权重。
之后通过f卷积和g卷积的输出计算权重,获得注意力图:
βj,i=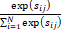 ,sij=f
,sij=f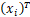 g
g (2)
(2)
式中,sij为xi向量与xj向量的相关程度;βj,i为sij经过softmax激活函数的结果,表征的是合成位于位置j的内容时,位置i的贡献程度。
最后将得到的注意力图与h卷积的输出做矩阵乘法作为最终自注意力层输出:
 (3)
(3)
自注意力层的输出是o,然后将o乘以一个比例系数γ,与输入x相加,得到最终输出yi。γ是一个可训练参数,一般初始化为0,表示在自注意训练过程中先关注局部信息,再逐渐学习全局信息。
2.3 生成器网络结构
生成器G被设计用来产生携带有光谱信息的模拟样本。如图3所示,生成器的输入用(z,y)表示,其中z是噪声向量,y 是经过独热编码处理的类别标签。通过将噪声向量与类别标签进行组合作为输入,生成器能够在训练阶段学习到与类别相关的独特特征,从而减小模型崩溃的可能性[33]。将G所生成的虚拟光谱用G(z,y)表示,并将这些生成的样本归类为第n+1类(其中n代表数据集类别数),同时为其赋予一个特定的人造标签yfake= 。
。
G由五个一维转置卷积层(1D-TConv)构成,每个卷积核大小为5。本文选择在G的最后一层嵌入自注意力层,因为经过五次转置卷积操作后,输出的特征图尺寸达到最大,此时引入自注意力机制能够发挥最佳效果。生成器中除了最后的转置卷积层采取双曲正切函数(tanh)作为激活函数外,其余各层均使用修正线性单元函数(Rectified Linear Units,ReLUs)作为非线性激活函数并采取批正则(Batch Normalization,BN)策略。
2.4 判别器网络结构
本文构建的判别器D用于完成对输入源的判别和多分类任务。如图4所示,其输入有两种来源:一种是真实影像的光谱,用X来表示;另一种是生成器生成的虚拟光谱,用G(z,y)来表示。文中分别用D(X)和D(G(z,y))分别代表判别器对真实数据和由生成器G产生的虚拟数据的判别输出。
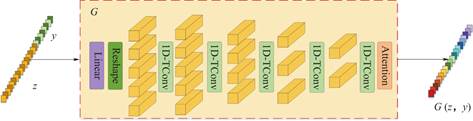
图3 生成器网络结构示意图
Fig.3 Schematic diagram of the generator network structure
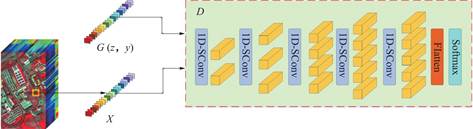
图4 判别器网络结构示意图
Fig.4 Schematic diagram of discriminator network structure
D包含五个一维步长卷积层(1D-SConv),每个卷积核大小为5。采用步长卷积代替池化操作,可以实现自适应学习下采样。经过5个1D-SConv操作所获取的光谱特征经过展平层(Flatten)转化为一维向量,随后被送入softmax层,以实现地物分类。判别器中所有的步长卷积层都采用带泄露的修正线性单元(Leaky-Rectified Linear Units,Leaky-ReLUs)作为激活函数。此外,除了输入层和输出层之外,判别器的每一层都实施了批正则策略。
2.5 损失函数
本章提出的网络MTGAN通过输入源判别任务、度量任务和地物分类任务的信息交互实现分类性能的提升。因此,MTGAN的损失函数主要由三部分组成,分别是对于输入源判别的二元交叉熵损失、度量任务的L2损失以及多分类的交叉熵损失。由于本文使用了一种多分类对抗策略,因此输入源的判别损失将融入多分类损失变为多类判别损失共同实现。
2.5.1 度量学习损失
度量学习[13]又被称作相似度学习。度量学习可以被理解为一种空间映射手段,使得同类样本的特征向量的相似度较大,而不同类的样本的特征向量的距离被拉远。传统的度量学习可以被分为直接度量和转换后度量两类,区别在于原始的特征空间是否被转换。比如K最近邻就是一种典型的直接度量方法,其通过欧氏距离在原始特征空间中进行度量。
随着深度学习的火热发展,深度度量学习成为训练深度学习网络的有力工具。深度学习可以对输入的数据进行非线性映射得到潜向量,深度度量学习在特征空间中通过特定的距离函数度量样本之间的距离以提升网络性能。常用的距离函数有余弦距离、L2距离等。
本文在生成器的损失函数中加入了L2距离度量损失,使得其生成的虚拟样本与真实样本经提取出的特征向量相匹配。从而避免生成器过度拟合当前的判别器,使得生成器生成更符合真实数据统计特性的样本。本文用Ls代表度量损失,具体的计算公式如下:
LS= (4)
(4)
式中,f(·)代表判别器D中的Flatten层的输出。
2.5.2 多类判别损失
传统生成对抗网络中的判别器仅借助sigmoid分类器实现对输入源的真假二值判别,在处理多分类任务时,通常会采用辅助分类器生成对抗网络 (ACGAN),其判别器中除sigmoid分类器以外,还引入了softmax分类器实现多分类任务。ACGAN的损失函数如下:
(ACGAN),其判别器中除sigmoid分类器以外,还引入了softmax分类器实现多分类任务。ACGAN的损失函数如下:
LD=LS+LC
LS=E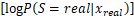 +
+
E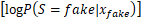
LC=E +
+
E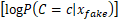 (5)
(5)
LG=LC-LS
LS=E(6)
LC=E
式中,LD代表判别器损失;LG代表生成器损失;LS代表输入源判别损失;Lc代表多分类交叉熵损失;xreal为真实样本;xfake为虚拟样本;c为类别标签。
由式(5)和(6)可知,ACGAN中的判别器的优化目标是既能对地物分类正确,又能正确分辨数据来源;而对于生成器而言,其优化目标是尽可能使判别器不能正确分辨假数据,且也希望对于地物能够正确分类。因此,ACGAN只针对sigmoid分类器对抗训练,而生成器和判别器对于softmax分类器的优化目标是一致的。
近些年,为了更好地完成多分类任务上的对抗训练,文献[15]设计了多类对抗策略,使得softmax层能够同时完成对输入源的判别和多分类任务;这种多类对抗策略也被应用到了本文所提出的MTGAN模型之中。MTGAN的生成器和判别器的多类判别损失定义如下:
 (7)
(7)
式中,CE(·)代表交叉熵;y为样本标签;yfake为人造标签;LG代表生成器损失函数;Ls代表度量学习损失;LD代表判别器损失函数;λ为超参数。
由式(7)可知,Lc表征虚拟样本G(z,y)相对于真实标签y的分类损失,Ls代表式(4)中的度量损失,超参数λ是平衡Lc与Ls的权重因子。Lreal代表真实样本X的分类损失,Lfake代表虚拟样本相对于人造标签yfake=的分类损失。生成器G的优化方向是促使判别器将生成的虚假样本准确归类到数据集中的某一类别,并力求生成的虚假样本与真实样本在判别器提取的特征向量上保持高度相似性。而判别器D的优化目标则聚焦于提高真实样本的多分类准确性,并将虚假样本准确识别为第n+1类。
2.6 实施流程
本文提出MTGAN的具体实施流程包括生成器生成虚拟样本,之后与真实影像的光谱一起输入给判别器进行多类判别以及度量匹配,最后通过多类判别损失以及度量学习损失对判别器和生成器进行交替优化,其算法实施流程如表1所示。
表1 MTGAN方法的算法实施流程
Table 1 Algorithm Implementation Process of MTGAN method
|
Input:训练样本Xtrain,测试样本Xtest,数据集类别数n,训练样本标签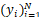 ,批处理数b,迭代次数e,噪声维度d ,批处理数b,迭代次数e,噪声维度d
|
|
1 初始化网络的权重和偏置
2 for every epoch
3 for every batch
4 采样d维度的噪声z=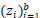
5 将噪声z和标签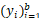 串联 串联
7 生成虚拟样本G(z,y)
8 以最小化LD为优化目标更新判别器D的参数
9 以最小化LG为优化目标更新生成器G的参数
10 end
11 end
Output:由判别器D预测的训练集Xtest的类别标签
|
3 实验设置与结果分析
3.1 实验所用高光谱图像数据集
3.1.1 Pavia University 数据集
Pavia University数据集是德国的机载ROSIS-03传感器在2003年的一次飞行实验中对意大利的帕维亚城所成像的一部分。该成像仪对430~860nm波长范围内的115个波段连续成像,去除12个噪声波段后,有103个波段可用。该数据集尺寸为610×340,共包含207400个像素,这些像素中有42776个像素被标识并被划分为9类地物,包括Trees,Asphalt,Brick等。本次实验每类随机抽取10%的标记样本用作训练,其余标记样本用作测试。表2展示了Pavia University数据集用于训练和测试的每个类别的可用样本分布。
表2 Pavia University数据集的可用样本分布
Table 2 Available sample distribution of Pavia University dataset
|
序号
|
类别
|
训练样本
|
测试样本
|
|
1
|
Asphalt
|
663
|
5968
|
|
2
|
Meadows
|
1865
|
16784
|
|
3
|
Gravel
|
210
|
1889
|
|
4
|
Trees
|
306
|
2758
|
|
5
|
Metal Sheets
|
134
|
1211
|
|
6
|
Bare Soil
|
503
|
4526
|
|
7
|
Bitumen
|
133
|
1197
|
|
8
|
Bricks
|
368
|
3314
|
|
9
|
Shadows
|
95
|
852
|
|
合计
|
|
4277
|
38499
|
3.1.2 Salinas数据集
第二个数据集源自机载可见光/红外成像光谱仪AVIRIS对美国加利福尼亚州Salinas山谷捕捉成像。该图像包含224个连续波段,在剔除掉被水吸收的波段后,还有204个波段被使用。该数据集尺寸为512×217,其中的标识像素有54129个,被分为16类,包括Fallow,Celery,Stubble等。同样随机抽取Salinas数据集每类10%的标记样本用作训练,其余标记样本用作测试。表3详细列出了Salinas数据集中各类别用于训练和测试的样本数目。
表3 Salinas数据集的可用样本分布
Table 3 Available sample distribution of Salinas dataset
|
序号
|
类别
|
训练样本
|
测试样本
|
|
1
|
Brocoli_green_weeds_1
|
201
|
1808
|
|
2
|
Brocoli_green_weeds_2
|
372
|
3354
|
|
3
|
Fallow
|
197
|
1779
|
|
4
|
Fallow_rough_plow
|
139
|
1255
|
|
5
|
Fallow_smooth
|
268
|
2410
|
|
6
|
Stubble
|
396
|
3563
|
|
7
|
Celery
|
358
|
3221
|
|
8
|
Grapes_untrained
|
1127
|
10144
|
|
9
|
Soil_vinyard_develop
|
620
|
5583
|
|
10
|
Corn_senesced_green
|
328
|
2950
|
|
11
|
Lettuce_romaine_4wk
|
107
|
961
|
|
12
|
Lettuce_romaine_5wk
|
193
|
1734
|
|
13
|
Lettuce_romaine_6wk
|
91
|
825
|
|
14
|
Lettuce_romaine_7wk
|
107
|
963
|
|
15
|
Vinyard_untrained
|
727
|
6541
|
|
16
|
Vinyard_vertical
|
181
|
1626
|
|
合计
|
|
5412
|
48717
|
3.2 实验设置
为了评估MTGAN模型的性能,本文将所提方法与五种典型的高光谱图像分类算法进行了对比,包括RBF-SVM[6],RF[5],GR ,LST
,LST 和1D-CNN[3]。此外,为了验证对抗训练的有效性和引入虚拟样本的优越性,本文还对只包含判别器的模型进行了分类对比实验,这个判别网络模型被命名为SCNN。对于提出的MTGAN方法,生成器和判别器的学习率设置为0.0002,epoch设置为200,batch size设置为64。在模型训练过程中,选择Adam优化算法来执行反向传播,以自适应的调节各参数的学习率。噪声z的维数被设置为100。SCNN的所有超参数的设置与MTGAN相同。另外,电脑配置NVIDIA 1080Ti显卡以实现GPU计算,所有实验代码均基于Python编程语言以及Pytorch框架实现。为了定量评价分类结果,本文选取总体分类精度(OA)、平均分类精度(AA)以及Kappa系数(κ)作为评价指标,具体计算公式见式(8)。由于模型可能受到不同初始化值的影响,在评估精度时取10次的实验结果的平均值和标准差作为最终分类精度。
和1D-CNN[3]。此外,为了验证对抗训练的有效性和引入虚拟样本的优越性,本文还对只包含判别器的模型进行了分类对比实验,这个判别网络模型被命名为SCNN。对于提出的MTGAN方法,生成器和判别器的学习率设置为0.0002,epoch设置为200,batch size设置为64。在模型训练过程中,选择Adam优化算法来执行反向传播,以自适应的调节各参数的学习率。噪声z的维数被设置为100。SCNN的所有超参数的设置与MTGAN相同。另外,电脑配置NVIDIA 1080Ti显卡以实现GPU计算,所有实验代码均基于Python编程语言以及Pytorch框架实现。为了定量评价分类结果,本文选取总体分类精度(OA)、平均分类精度(AA)以及Kappa系数(κ)作为评价指标,具体计算公式见式(8)。由于模型可能受到不同初始化值的影响,在评估精度时取10次的实验结果的平均值和标准差作为最终分类精度。
OA=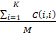
AA= (8)
(8)
Kappa=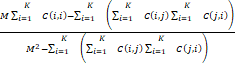
式中,C代表混淆矩阵;M代表训练样本总数;K代表数据集类别数;C(i,j)代表j类的样本被判别为i类样本的数量。
3.3 分类结果与可视化
表4和表5分别展示了RBF-SVM,RF,GRU,LSTM,1D-CNN,SCNN以及MTGAN 7种方法在两个数据集上的分类结果。表格记录了每种方法运行十次后的每类精度、OA、AA和Kappa系数的均值,且后三个评价指标提供了标准差。表中加粗的数字代表该方法在对应指标中取得最佳结果。
从表4和表5可以看出,鉴于深度学习方法擅长提取高层次的非线性特征,MTGAN和SCNN方法的分类精度普遍高于传统的RBF-SVM和RF方法。MTGAN在两个数据集上均取得了最佳结果:对于Pavia University数据集,MTGAN相对于GRU、LSTM、1D-CNN和SCNN四种深度学习方法,OA分别提升了1.25%、0.97%、5.37%和0.42%;在Salinas数据集上,MTGAN有10类地物取得了最佳预测精度,11类地物达到99%以上的分类准确率,OA的10次平均值达到95.11%,充分证明了对抗训练的有效性以及利用虚拟样本的优越性。
除了表4至表5对分类结果的定量表述,本文还通过绘制两个高光谱数据集上每种方法的预测结果图对分类结果进行定性分析。如图5至图6所示,图中各色块代表了不同的地物类别。可以看出本文提出的MTGAN方法在两个数据集上得到的预测图相较于其他方法更接近于真实标签图,分类图中存在更少的离群值,类别边界更清晰,这进一步证明了MTGAN模型的有效性。
表4 各方法在Pavia University数据集上的分类结果
Table 4 Classification results of the Pavia University dataset
|
序号
|
RBF-SVM
|
RF
|
GRU
|
LSTM
|
1D-CNN
|
SCNN
|
MTGAN
|
|
1
|
90.70
|
91.26
|
94.49
|
93.80
|
90.83
|
94.44
|
95.33
|
|
2
|
93.77
|
97.54
|
97.27
|
97.96
|
93.5
|
98.45
|
98.49
|
|
3
|
83.89
|
66.28
|
73.89
|
80.38
|
76.36
|
76.92
|
75.71
|
|
4
|
96.22
|
89.15
|
94.74
|
93.03
|
94.93
|
96.39
|
96.45
|
|
5
|
99.25
|
98.90
|
99.94
|
99.29
|
99.32
|
99.76
|
99.79
|
|
6
|
91.21
|
64.54
|
91.74
|
90.60
|
84.75
|
92.48
|
92.46
|
|
7
|
83.24
|
76.75
|
86.3
|
85.82
|
84.03
|
88.02
|
90.11
|
|
8
|
84.61
|
89.48
|
88.6
|
89.40
|
76.96
|
87.61
|
88.93
|
|
9
|
99.97
|
99.37
|
99.86
|
99.54
|
93.42
|
99.81
|
99.79
|
|
OA(%)
|
91.95±1.34
|
89.29±0.25
|
93.91±0.1
|
94.19±0.22
|
89.79±0.12
|
94.74±0.11
|
95.16±0.11
|
|
AA(%)
|
91.43±0.02
|
85.92±0.05
|
91.87±0.3
|
92.20±1.13
|
87.13±0.48
|
92.65±0.3
|
93.01±0.32
|
|
κ×100
|
89.24±0.02
|
85.57±0.32
|
91.93±0.12
|
92.28±0.30
|
86.4±0.2
|
93.02±0.14
|
93.38±0.15
|
表5 各方法在Salinas数据集上的分类结果
Table 5 Classification results of various methods on the Salinas dataset
|
序号
|
RBF-SVM
|
RF
|
GRU
|
LSTM
|
1D-CNN
|
SCNN
|
MTGAN
|
|
1
|
99.96
|
99.42
|
99.62
|
99.62
|
98.9
|
99.68
|
99.76
|
|
2
|
99.74
|
99.92
|
99.95
|
99.89
|
98.9
|
99.97
|
99.98
|
|
3
|
98.64
|
98.66
|
99.39
|
99.05
|
95.69
|
99.71
|
99.8
|
|
4
|
99.14
|
99.21
|
99.2
|
99.31
|
98.83
|
99.63
|
99.62
|
|
5
|
99
|
98.24
|
99.2
|
98.85
|
96.95
|
98.88
|
99.07
|
|
6
|
99.67
|
99.69
|
99.87
|
99.84
|
99.29
|
99.79
|
99.74
|
|
7
|
99.94
|
99.40
|
99.95
|
99.63
|
99.25
|
99.71
|
99.63
|
|
8
|
80.76
|
86.84
|
90.72
|
86.31
|
81.5
|
89.58
|
91.03
|
|
9
|
99.49
|
99.30
|
99.86
|
99.86
|
98.5
|
99.92
|
99.94
|
|
10
|
98.51
|
92.53
|
97.7
|
95.96
|
94.42
|
97.54
|
97.85
|
|
11
|
99.48
|
95.10
|
97.29
|
98.05
|
93.12
|
98.61
|
99.75
|
|
12
|
99.42
|
99.22
|
99.93
|
99.61
|
94.46
|
99.97
|
99.98
|
|
13
|
98.67
|
97.67
|
99.06
|
98.88
|
94.06
|
98.13
|
98.4
|
|
14
|
97.92
|
93.47
|
98.32
|
97.11
|
94.96
|
96.15
|
96.68
|
|
15
|
83.59
|
65.90
|
72.31
|
77.94
|
75.97
|
77.54
|
80.46
|
|
16
|
99.77
|
97.78
|
99.43
|
98.81
|
99.01
|
99.11
|
99.13
|
|
OA(%)
|
93.31±0.07
|
91.54±0.15
|
93.96±0.15
|
93.59±0.36
|
91.27±0.34
|
94.36±0.1
|
95.11±0.1
|
|
AA(%)
|
97.12±0.08
|
95.15±0.15
|
96.99±0.1
|
96.40±1.07
|
94.66±0.41
|
97.12±0.13
|
97.41±0.14
|
|
κ ×100
|
92.53±0.08
|
90.56±0.17
|
93.26±0.18
|
92.86±0.44
|
90.27±0.37
|
93.12±0.1
|
94.30±0.11
|
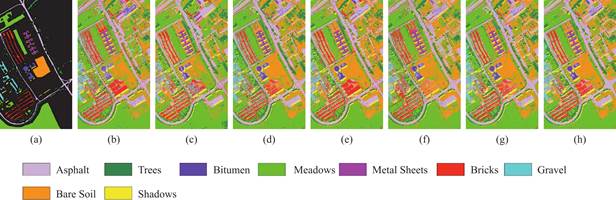
图5 Pavia University数据集上的分类可视化图(a)Ground truth,(b)RBF-SVM,(c)RF,(d)GRU,(e)LSTM,(f)1D-CNN,(g)SCNN,and(h)MTGAN
Fig.5 Classification maps of different models on the Pavia University dataset (a)Ground truth,(b)RBF-SVM,(c)RF,(d)GRU,(e)LSTM,(f)1D-CNN,(g)SCNN,and(h)MTGAN
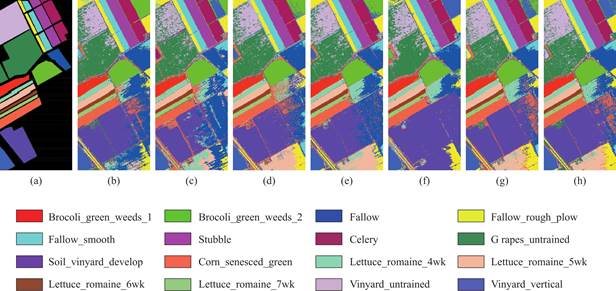
图6 Salinas数据集上的分类可视化图(a)Ground truth,(b)RBF-SVM,(c)RF,(d)GRU,(e)LSTM,(f)1D-CNN,(g)SCNN,and(h)MTGAN
Fig.6 Classification maps of different models on the Salinas dataset (a)Ground truth,(b)RBF-SVM,(c)RF,(d)GRU,(e)LSTM,(f)1D-CNN,(g)SCNN,and(h)MTGAN
3.4 超参数λ最优选择分析
公式(7)中的λ是平衡Lc与Ls的权重因子,为了探究λ的取值对分类结果的影响,本文在0到0.5范围内以0.1为间隔选取λ的值进行实验。表6是在两个数据集上的计算结果。对于Pavia University数据集,λ=0.4时OA最高。对于Salinas数据集,最高精度对应的λ为0.1。根据以上实验结果,本章在进行对比实验时,将λ设置为两个数据集对应的最佳值。此外,当λ=0时,网络不依靠度量学习损失进行训练,分类精度相对较低,这说明多任务联合训练能够提高网络的分类性能。
3.5 训练样本数目敏感性分析
为了考察不同分类方法对于训练样本数量的依赖性,本文在两个数据集上依次随机抽取10%、9%、8%、7%和6%的标记样本对7种方法进行训练。如图7所示,随着训练样本的减少,7种方法的分类精度均呈现出不同程度的下滑趋势。尤其基于深度学习的方法需要大量的训练样本来优化参数,下降的幅度较为明显。而MTGAN依靠生成假样本,能一定程度的减轻训练样本减少带来的过拟合问题,下降幅度相对较小。与这些方法相比,MTGAN在不同比例的训练样本下都能提供最佳的分类性能,在Pavia University数据集和Salinas数据集上OA最大下降幅度分别为1.02%和0.66%,下降速度最慢。
表6 在两个数据集上不同λ值下的总体分类精度
Table 6 Overall accuracy upon two datasets with different values of λ
|
λ
|
0
|
0.1
|
0.2
|
0.3
|
0.4
|
0.5
|
|
Pavia University
|
95.11
|
95
|
95.08
|
95.02
|
95.16
|
95.11
|
|
Salinas
|
94.96
|
95.11
|
94.81
|
94.9
|
94.98
|
95.08
|
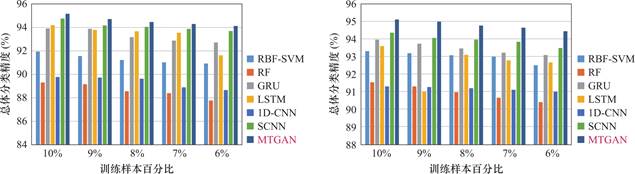
图7 两个数据集上不同比例训练样本下的各方法的总体分类精度
(a)Pavia University数据集,(b)Salinas数据集
Fig.7 Overall classification accuracy of various methods with different ratios of training samples on two datasets
(a)Pavia University dataset,(b)Salinas dataset
4 结论
针对高光谱图像分类领域中传统方法提取特征能力差以及深度学习方法标记样本有限情况下容易过拟合的问题,本章提出了基于光谱度量和多类判别的多任务生成对抗网络(MTGAN)。网络中的生成器生成虚拟光谱曲线扩充训练样本,以减轻网络对于标记样本的依赖性。同时,本文在生成器的末端设置了自注意力机制模块,以更好地关注高光谱数据的长程依赖关系。网络中的判别器通过采用多类对抗策略,将输入源的判别损失融入多分类损失变为多类判别损失共同实现,更好地完成了多分类任务上的对抗训练。此外,通过为生成器设置度量任务,防止生成器对当前尚未充分训练的判别器产生过度拟合现象,进而达到提升网络稳定性的目的。最终,MTGAN通过度量学习损失和多类判别损失进行优化。在实验部分首先介绍了实验所用的数据集以及涉及方法的参数设置,之后对于分类结果进行了定量、定性分析,最终又针对多任务架构有效性和训练样本数量敏感性进行讨论。在两个标准数据集上的实验结果表明,MTGAN依靠样本扩充以及多任务学习架构表现出相对优异的分类性能,并且对训练样本的数量表现出较低的依赖性,这表明多任务生成对抗网络在标记样本有限情况下具有较大的应用潜力。
利益冲突: 作者声明无利益冲突。
[④] 通讯作者 Corresponding author:汤云贺,411205572@qq.com
收稿日期:2025-03-13; 录用日期:2025-03-19; 发表日期:2025-03-28
参考文献(References)
[1] 李军吉, 费佳宁, 周婷, 等. 利用高光谱数据估算城市植被碳储量[J]. 测绘通报, 2023(04): 106-110.
https://doi.org/10.13474/j.cnki.11-2246.2023.0112.
[2] 赵冬雪. 基于多尺度高光谱技术的水稻叶瘟病检测方法研究[D]. 沈阳: 沈阳农业大学, 2024.
https://doi.org/10.27327/d.cnki.gshnu.2024.000060.
[3] 殷一涵, 李美轩, 秦思彤, 等. 高光谱技术在矿业中的应用与发展分析[J]. 当代化工研究, 2024(20): 18-20.
https://doi.org/10.20087/j.cnki.1672-8114.2024.20.006.
[4] 高新新. 基于高光谱图像异常信息的伪装目标识别研究[D]. 哈尔滨: 哈尔滨工程大学, 2024.
https://doi.org/10.27060/d.cnki.ghbcu.2024.001608.
[5] Ham J, Chen Y, Crawford M M, et al. Investigation of the random forest framework for classification of hyperspectral data[J]. IEEE Transactions on Geoscience & Remote Sensing, 2005, 43(3): 492-501.
https://doi.org/10.1109/TGRS.2004.842481.
[6] Zhong S, Chang C I, Ye Z. Iterative Support Vector Machine for Hyperspectral Image Classification[C]//IEEE International Conference on Image Processing, 2018: 3309-3312.
https://doi.org/10.1109/ICIP.2018.8451145.
[7] Hu W, Huang Y, Wei L, et al. Deep convolutional neural networks for hyperspectral image classification[J]. Journal of Sensors, 2015: 1-12.
https://doi.org/10.1155/2015/258619.
[8] Li W, Wu G, Fan Z, et al. Hyperspectral Image Classification Using Deep Pixel-Pair Features[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 55(2): 1-10.
https://doi.org/10.1109/TGRS.2016.2616355.
[9] 孟龙祥, 李奇. 基于文本-光谱特征联合学习的高光谱图像分类算法[J]. 电脑与信息技术, 2024, 32(05): 7-11.
https://doi.org/10.19414/j.cnki.1005-1228.2024.05.017.
[10] 李子轩, 官云兰, 王楠, 等. 基于卷积神经网络的高光谱图像分类[J]. 江西科学, 2025, 43(01): 26-35.
https://doi.org/10.13990/j.issn1001-3679.2025.01.004.
[11] Li X, Li Z, Qiu H, et al. An overview of hyperspectral image feature extraction, classification methods and the methods based on small samples[J]. Applied Spectroscopy Reviews, 2021, 106: 104346.
https://doi.org/10.1080/05704928.2021.1999252.
[12] Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need[C]//International Conference on Neural Information Processing Systems, 2017: 5999-6009.
https://doi.org/10.48550/arXiv.1706.03762
[13] Yang L, Jin R. Distance Metric Learning: A Comprehensive Survey[J]. Michigan State University, 2006, 2(2): 4.
[14] Odena A, Olah C, Shlens J. Conditional Image Synthesis with Auxiliary Classifier GANs[C]//International Conference on Machine Learning, 2017: 4043-4055.
https://doi.org/10.48550/arXiv.1610.09585
[15] Feng J, Yu H, Wang L, et al. Classification of Hyperspectral Images Based on Multiclass Spatial-Spectral Generative Adversarial Networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(8): 5329-5343.
https://doi.org/10.1109/TGRS.2019.2899057.
[16] Cho K, Van Merrienboer B, Bahdanau D, et al. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches[C]// In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, 2014: 103-111.
https://doi.org/10.48550/arXiv.1409.1259
[17] Xu Y, Zhang L, Du B, et al. Spectral-Spatial Unified Networks for Hyperspectral Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(10): 1-17.
https://doi.org/10.1109/TGRS.2018.2827407.
Research on Hyperspectral Image Classification Based on Multi-task Generative Adversarial Networks
TANG Yunhe
(Suzhou Aerospace Information Research Institute, Suzhou 215124, China)
Abstract: As a prerequisite to realize many applications of hyperspectral images, hyperspectral image classification has been a hot and difficult research area in remote sensing. In recent years, various deep learning network models are in the ascendant and gradually applied to hyperspectral image classification. However, hyperspectral image datasets often have the problems of sparse labeled samples and uneven class distribution, which lead to the overfitting phenomenon of networks when the training samples are limited and achieve low classification accuracy. In order to solve the above problems, this paper deeply investigates generative adversarial networks and improves them, while combining them with multi-task learning to propose hyperspectral classification methods based on multi-task generative adversarial networks. The algorithm achieves deep mining of hyperspectral data features by efficiently training the generator and discriminator, in which the generator produces a large number of virtual samples to expand the training set, and the discriminator relies on the information interaction of the input source discrimination task, the metric task and the ground object classification task to improve the classification performance. The proposed method has validated the effectiveness of each module on two standard datasets, and demonstrated that the method can exhibit relatively excellent classification performance through sample expansion and multi-task learning architecture, with low dependence on the number of training samples.
Keywords: Hyperspectral image classification, generative adversarial networks, multi-task learning, sample expansion
DOI: 10.48014/ais.20250313001
Citation: TANG Yunhe. Research on hyperspectral image classification based on multi-task generative adversarial networks[J]. Acta Interdisciplinary Science, 2025, 2(1): 37-47.
