一种提升攻击能力的降信息对抗样本方法
李施旻*, 张用明
(南京航空航天大学计算机科学与技术学院, 南京211100)
摘要: 当前, 深度神经网络在多个研究领域中得到广泛应用。但随着对人工智能研究的深入, 研究者发现基于深度神经网络的人工智能技术在带来便利的同时也存在安全隐患。例如, 攻击者使用对抗样本方法在干净图像中添加细微扰动, 可导致图像分类模型输出错误的结果。相较于以往在图像上添加额外信息产生对抗样本的方法, Duan Ranjie等人近期提出了AdvDrop算法。该算法通过调整量化步长来删除图像的现有信息从而生成对抗样本, 但AdvDrop在量化过程中并未考虑量化表不同的梯度数值对于对抗效果的不同影响。对此, 本文提出AdvDrop+, 即在每次迭代过程中根据量化表的梯度数值来更新量化表。梯度数值被一个缩放因子所缩放。为了找到合适的缩放因子, AdvDrop+在梯度直方图中找到最高频率的梯度值, 并计算其对数, 最终得到的结果即为缩放因子。实验表明, 在目标攻击的设置下, 图像失真几近相同, AdvDrop+有着比AdvDrop更好的攻击性能。同时, AdvDrop+保留了AdvDrop能够降信息的特点。
关键词: 神经网络, 对抗样本, 图像分类, 降信息
DOI: 10.48014/ccsr.20231107001
引用格式: 李施旻, 张用明. 一种提升攻击能力的降信息对抗样本方法[J]. 中国计算机科学评论, 2024, 2(2): 14-23.
文章类型: 研究性论文
收稿日期: 2023-11-07
接收日期: 2023-11-23
出版日期: 2024-06-28
1 引言
深度神经网络在计算机视觉[1]、自然语言处理[2]、生物信息学[3]、医疗诊断[4]和语音识别 等研究领域中都应用广泛,扮演着不可或缺的重要角色,促进了相关产业的发展和社会生产力的变革。但随着对人工智能研究的不断深入,基于神经网络的人工智能技术在提供快捷方便的同时也伴随着各种各样的安全隐患,如数据投毒、模型窃取[7]、后门攻击、对抗样本[8]等。
等研究领域中都应用广泛,扮演着不可或缺的重要角色,促进了相关产业的发展和社会生产力的变革。但随着对人工智能研究的不断深入,基于神经网络的人工智能技术在提供快捷方便的同时也伴随着各种各样的安全隐患,如数据投毒、模型窃取[7]、后门攻击、对抗样本[8]等。
在这些人工智能安全隐患中较为出名的为对抗样本。Szegedy等人在发表的论文中首次提出了对抗样本。他们发现在输入样本中增加部分人眼难以发觉的细微干扰,可导致模型以高置信度给出一个错误的分类结果。
在人工智能领域当中运用对抗样本攻击神经网络,带来的危害是具有现实意义的,比如误导无人驾驶[9]、干扰人脸识别[10]、影响恶意软件的检测效果[11],等等。以无人驾驶汽车为例,这些车辆依赖于多种关键技术,包括激光测距器、人工智能、车联网、监控设备以及高精度定位系统等,以收集路面信息。算法通过对这些输入数据进行综合分析和判断,使计算机能够自主、安全地驾驶汽车,而无须人为干预。然而,对于具备自动交通标志识别能力的无人驾驶系统,存在着一种特殊的威胁,即对抗攻击。攻击者可以通过操纵输入数据,使自动识别系统错误地识别交通标志或交通信号灯,从而导致无人驾驶汽车采取潜在危险的行动,最终造成严重的交通事故。除此之外,日常生活中攻击者也可使用对抗样本面具来伪装成合法用户,欺骗智能手机的人脸识别系统,造成个人身份信息泄露和财产损失。一方面,攻击者采用对抗样本进行攻击的可能性限制了神经网络的应用领域,另一方面,对抗样本也可以作为评估神经网络模型安全性和鲁棒性的有效工具[12]。因此,对抗样本对神经网络安全性的研究有很大的现实意义,适当应用能在信息安全和隐私保护等方面发挥重要的作用[13]。
产生对抗样本的过程为对抗攻击。根据攻击者能够获取的目标模型信息的多少,可以将对抗攻击分成两种类型,即白盒攻击 和黑盒攻击
和黑盒攻击 。在白盒攻击的情境下,攻击者可以访问目标模型的所有信息,包括模型参数、梯度和网络结构等。相反,在黑盒攻击的背景下,攻击者只能获取模型返回的部分信息,例如输出的概率或标签,但无法了解模型的具体训练过程和参数。尽管在实际应用中,攻击者通常难以获知目标模型的详细信息,但值得注意的是,目前大部分模型基于开源的机器学习框架构建,这为攻击者攻击模型提供了可能性。攻击者可以利用这些开源框架来执行白盒攻击,从而在理论上实现与目标模型相似的效果。
。在白盒攻击的情境下,攻击者可以访问目标模型的所有信息,包括模型参数、梯度和网络结构等。相反,在黑盒攻击的背景下,攻击者只能获取模型返回的部分信息,例如输出的概率或标签,但无法了解模型的具体训练过程和参数。尽管在实际应用中,攻击者通常难以获知目标模型的详细信息,但值得注意的是,目前大部分模型基于开源的机器学习框架构建,这为攻击者攻击模型提供了可能性。攻击者可以利用这些开源框架来执行白盒攻击,从而在理论上实现与目标模型相似的效果。
学术界提出了多种假设来解释神经网络在对抗性样本中的脆弱性,涵盖多个角度,包括高维非线性假设[10]、线性假设[16]、边界倾斜假设[17]、高维流行假设[18]、缺乏足够的训练数据[19]以及非鲁棒特征的假设[20]等。虽然这个问题还远未被完全解决,但当前最直接的解释是神经网络的脆弱性来自数据分布衍生的特征。
目前有多种方法生成对抗样本。相较于以往在图像上增加细微扰动和增加图像存储空间的方法,Duan Ranjie等[21]以新颖的角度提出一种新型的对抗攻击——AdvDrop。该算法主要从干净的图像中删除某些人类肉眼无法察觉但对DNNs(Deep Neural Networks,DNNs)至关重要的特征,导致DNNs无法识别最终图像,产生错误的分类结果。图像信息的减少可以在空域(如颜色量化)或频域(如JPEG压缩)实现。而AdvDrop当前的研究主要集中在频域,这种选择的动机是基于人类的眼睛天生对图像细节不敏感这一规律。具体地,该方法首先将原始图像从空域变换到频域,然后对变换后图像中的部分频率分量进行定量缩减。AdvDrop的主要工作在于采用了可训练的量化表和改进的可微分量化函数来达到降信息,即删减图像信息的目的,从而产生对抗样本。但AdvDrop 在对量化表的更新过程中仅考虑量化表的梯度符号部分而忽视了量化表的梯度数值部分对对抗效果产生的不同影响。对此,本文提出AdvDrop+,即在每次迭代过程中根据量化表的梯度数值来更新量化表。梯度数值被一个缩放因子所缩放。为了找到合适的缩放因子,AdvDrop+ 在梯度直方图中找到最高频率的梯度值,并计算其对数,从而进一步减少相对次要的图像信息,达到更好的对抗效果。AdvDrop+的改进主要针对目标攻击设置,即攻击者可以要求目标模型将对抗样本错误分类到特定类别。在目标攻击的设置下,对抗攻击更具有针对性,也更具有威胁性。实验表明,AdvDrop+在保留AdvDrop降信息特点的同时,攻击性能优于AdvDrop。
本文以下内容按照如下组织。首先,第二章简要介绍深度神经网络与目前较主流的白盒对抗攻击方法并对AdvDrop进行简要介绍。接着,第三章具体介绍了本文的改进措施。然后,第四章详细叙述实验结果并对实验结果展开分析。最后,第五章总结了本文的主要工作,并对未来的工作提出几点展望。
2 相关工作
2.1 深度神经网络
深度神经网络,受启发于生物神经结构,它是由神经元层组织形成的大型神经网络,对应于输入数据的连续表示。典型的神经网络结构如图1所示。
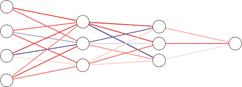
图1 DNNs的基本结构
Fig.1 Basic structure of DNNs
其中,圆圈代表独立的计算单元,神经元,它是DNNs中的最小单位。图的前端是输入层,该层用于接收多个输入的数据值。这些数据值经由前向传播传到神经网络中间层的神经元中,中间层也常称为神经网络的隐藏层。具有多个隐藏层的架构可以显著增强模型的表达能力。这些隐藏层的加权和最终前向传播到输出层,输出层将神经网络的最终结果输出。
2.2 对抗攻击
在白盒攻击的设置中,攻击者可以访问目标模型的所有信息,包括模型参数、梯度、网络结构等。按照攻击方法划分,可以将白盒攻击分为单步攻击、迭代攻击、基于优化的攻击和其他白盒攻击。
(1)快速梯度符号法(Fast Gradient Sign Method,FGSM)和快速梯度方法(Fast Gradient Method,FGM)
FGSM[8]是典型的单步攻击算法,在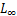 范数距离下产生对抗样本。如公式(1)所示,FGSM通过计算相对于图像的损失梯度,乘上常数生成一个细微的扰动,再添加到原始图像
范数距离下产生对抗样本。如公式(1)所示,FGSM通过计算相对于图像的损失梯度,乘上常数生成一个细微的扰动,再添加到原始图像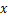 中,形成对抗样本。直观地说,FGSM的主要思想是通过一步运算增大分类器的损失函数,降低分类的置信度,生成对抗样本。
中,形成对抗样本。直观地说,FGSM的主要思想是通过一步运算增大分类器的损失函数,降低分类的置信度,生成对抗样本。
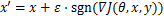 (1)
(1)
与FGSM采用符号函数对梯度进行max归一化操作不同,FGM采用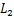 归一化,如公式(3)所示:
归一化,如公式(3)所示:
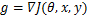 (2)
(2)
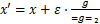 (3)
(3)
FGM生成的对抗样本需要满足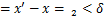 。
。
(2)基本迭代法(Basic Iteration Method,BIM)和投影梯度下降法(Project Gradient Descent,PGD)
BIM[22]是FGSM的扩展之一,是FGSM的多次迭代版本。BIM以较小的步长将FGSM多次运用,并在每次运用之后对图像进行裁剪,确保图像像素在规定的范围之内,如公式(4)所示。
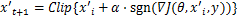 (4)
(4)
PGD[23]可看作是BIM的广义形式。如公式(5)所示。PGD将大步长分解为小步长,进行多次迭代,逐步增加目标模型的损失。每次迭代后若扰动超过一定的范围,PGD会将其投影回规定的范围内。PGD和BIM的区别在于初始化会有一个随机的扰动,PGD并不是从0开始的。
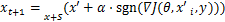 (5)
(5)
(3)JSMA算法(Jacobian-based Saliency Map Attack,JSMA)
JSMA[24]算法是基于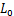 距离的攻击算法。与FGSM利用目标模型输出的损失函数梯度信息不同,JSMA主要利用目标模型的输出类别概率来反向传播求得对应的梯度信息。作者将其称为前向导数,如公式(6)所示:
距离的攻击算法。与FGSM利用目标模型输出的损失函数梯度信息不同,JSMA主要利用目标模型的输出类别概率来反向传播求得对应的梯度信息。作者将其称为前向导数,如公式(6)所示:
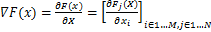 (6)
(6)
其中,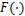 表示神经网络函数,
表示神经网络函数,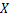 为输入样本,
为输入样本,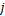 表示对应的输出分类,
表示对应的输出分类,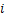 表示对应的输入特征。通过前向梯度,攻击者可以知道图像中每个像素点对模型分类结果的影响程度,进而利用前向梯度信息来更新干净图像。
表示对应的输入特征。通过前向梯度,攻击者可以知道图像中每个像素点对模型分类结果的影响程度,进而利用前向梯度信息来更新干净图像。
(4)DeepFool算法
DeepFool[25]算法主要用于计算和比较不同分类器对对抗样本的鲁棒性。相较于FGSM中没有对样本扰动范围进行界定,DeepFool算法思想是寻找图像到决策边界的最短距离,跨过决策边界,改变图像分类结果,欺骗目标模型。该算法最小的对抗扰动,是样本到多分类分类器最接近决策分类边界的距离。
(5)C&W算法(Carlini and Wagner Attacks,C&W)
C&W[26]是一种基于优化的攻击算法。该算法主要基于三种距离度量,分别是、、范数距离。如公式(7)所示,C&W算法可以描述为约束最小化问题。其中,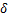 为对抗扰动,
为对抗扰动,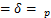 为对抗样本与干净样本的距离,
为对抗样本与干净样本的距离,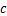 为超参数,用于权衡两个损失之间的关系。
为超参数,用于权衡两个损失之间的关系。
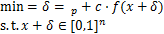 (7)
(7)
但在实际生成过程中,对抗样本可能超出原有的像素范围。为确保生成图片的有效性,C&W算法引入新的变量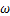 ,如公式(8)所示,并将其映射到tanh空间。
,如公式(8)所示,并将其映射到tanh空间。
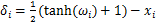 (8)
(8)
2.3 AdvDrop介绍
Szegedy等人最先提出对抗样本,此后学术界提出了多种假设来解释对抗样本的生成与神经网络的脆弱性。在众多假设中,Ilyas等[20]提出了一种设想,他们认为对抗样本不是毫无根据的错误,而是人眼不可感知的神经网络的一种数据特征。
受启发于Ilyas 等人的工作,Duan Ranjie等人试图从相反的角度来讨论一个潜在的对抗攻击机制,即去掉一些人眼不可感知但对于模型决策又至关重要的特征,生成对抗样本。Duan Ranjie等人认为以往对抗攻击产生的对抗样本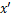 均可被视为
均可被视为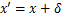 ,而AdvDrop产生的对抗样本可被视为
,而AdvDrop产生的对抗样本可被视为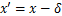 ,其中,表示信息量。这里的“+”和“-”并不指对图像值进行简单的“加”或者“减”操作,而是表示前者中的是由攻击产生的额外信息,后者中的是由AdvDrop算法删除的干净图像的现有信息。它们都可被视为添加在图像上的对抗扰动。
,其中,表示信息量。这里的“+”和“-”并不指对图像值进行简单的“加”或者“减”操作,而是表示前者中的是由攻击产生的额外信息,后者中的是由AdvDrop算法删除的干净图像的现有信息。它们都可被视为添加在图像上的对抗扰动。
为选择区域丢失图片的信息,Duan Ranjie等人提出一种通过优化量化表的方式来选择丢弃信息的区域以及丢弃的图像信息量。同时,为了保证丢失的图像细节对于人眼来说依然不可感知,AdvDrop对图像的降信息操作被选择在频域上进行。频域操作相比于空域的优点是,它能够更好地分离图像的细节信息(高频信息)和结构信息(低频信息),保证人眼无法察觉丢失的图像细节。
具体地,AdvDrop生成对抗样本的过程如下:
(1)将输入图像进行分块处理,分成8 × 8大小的子块;
(2)对每个图像子块进行离散余弦变换,用不同频率振荡的和余弦函数来表示有限的数据点序列;
(3)在量化过程中使用可微分的改进量化函数对离散余弦变换系数进行量化处理;
(4)通过神经网络模型对量化表进行训练,更新量化表;
(5)对子块进行离散余弦逆变换操作,将变换图像的信号从频域恢复到空间域,从离散余弦变换系数中重建序列;
(6)合并图像子块,生成对抗样本;
(7)将对抗样本送入目标模型,计算对抗攻击成功率;
(8)重复以上步骤,直至达到最大的迭代次数或攻击成功率大于等于1。
(9)对图像像素进行裁剪,返回最终的对抗样本。
在对抗样本的生成过程中,AdvDrop采用可训练的量化表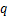 来量化转换后的图像。在目标函数的优化过程中,AdvDrop 通过反向传播返回的梯度序列更新量化表,如公式(9)所示:
来量化转换后的图像。在目标函数的优化过程中,AdvDrop 通过反向传播返回的梯度序列更新量化表,如公式(9)所示:
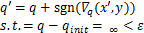 (9)
(9)
其中,sgn(.)函数返回一个整型变量,用于指出参数的正负号。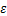 的目的与
的目的与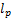 范数相似,旨在让生成的对抗图像与干净图像看起来没有区别,保证人眼的不可察觉性。限制了量化表,以进一步限制要丢失的图像信息量。
范数相似,旨在让生成的对抗图像与干净图像看起来没有区别,保证人眼的不可察觉性。限制了量化表,以进一步限制要丢失的图像信息量。
3 方法构建
本篇文章使用的基本概念和假设如表1所示。
表1 符号及其描述
Table 1 Symbols and their descriptions
|
符号
|
描述
|
|
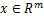
|
干净样本
|
|
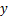
|
正确分类标签
|
|
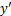
|
目标攻击标签
|
|
|
对抗样本
|
|
|
量化表
|
|
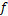
|
目标模型
|
|
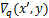
|
量化表的梯度
|
|
|
梯度缩放参数
|
|
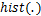
|
梯度分布统计函数,输入量化表梯度张量,返回梯度幂指数取值的个数序列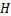 和梯度幂指数可取数值序列 和梯度幂指数可取数值序列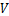
|
由公式(9)可知,AdvDrop在对量化表的更新过程中,仅关注量化表的梯度符号部分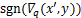 ,而忽略了量化表梯度的数值部分。即在相同符号下,无论梯度数值的大小是多少,最后更新的量化表的步长都相同,为。这引发了一个问题:在每次攻击的迭代过程中,量化表的梯度数值差异如何?梯度的数值差异对攻击效果是否有影响?
,而忽略了量化表梯度的数值部分。即在相同符号下,无论梯度数值的大小是多少,最后更新的量化表的步长都相同,为。这引发了一个问题:在每次攻击的迭代过程中,量化表的梯度数值差异如何?梯度的数值差异对攻击效果是否有影响?
由此本文分析了不同图像块位置所对应的量化表梯度。从图2可以看出,图像中不同的图像分块处于不同的位置会具有不同的图像内容,不同位置的图像内容图片信息不一样;同时每个图像分块都对应各自的量化表,该表会在对抗过程中对图像进行量化。这两者决定了不同的量化表块的梯度数值会有明显的不一样,如图2中的黑色方格所示。颜色越深表示梯度数值越大,反之梯度数值越小。因此本文决定将量化表的梯度数值部分作为更新量化表的依据,以更准确地反映不同图像分块的特征差异,从而优化攻击效果。

图2 不同图像块位置对应的量化表梯度
Fig.2 Quantization table gradients corresponding to different image blocks
为了详细说明以梯度数值为依据更新量化表的过程,本文进一步分析了量化表数值的梯度分布,以某个图像块所对应的量化表为例。图3展示了该量化表的梯度数值分布,描述了图像块中各位置处的梯度数值分布情况。这一分布是通过计算图像梯度并对梯度数值进行幂指数运算得到的。由图3可知,该图像所对应的量化表的梯度幂指数数值小,差别大,主要集中在10-1到10-10之间。一方面,若将量化表的更新过程更改为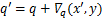 ,则由于梯度数值太小,会导致在攻击过程中反向传播无法对量化表的更新产生实质性影响,为此需要对量化表进行缩放以提升对抗效率。而另一方面,不同的图像在生成对抗样本过程的不同阶段中,梯度分布差异较大,如果对所有的图像均采用固定的缩放因子,可能会造成在迭代过程中梯度对抗修改不足或者梯度修正步长过大的问题。因此在对量化表的更新过程中,每次迭代均需要根据图像的对抗梯度分布动态选择合适的缩放因子。
,则由于梯度数值太小,会导致在攻击过程中反向传播无法对量化表的更新产生实质性影响,为此需要对量化表进行缩放以提升对抗效率。而另一方面,不同的图像在生成对抗样本过程的不同阶段中,梯度分布差异较大,如果对所有的图像均采用固定的缩放因子,可能会造成在迭代过程中梯度对抗修改不足或者梯度修正步长过大的问题。因此在对量化表的更新过程中,每次迭代均需要根据图像的对抗梯度分布动态选择合适的缩放因子。
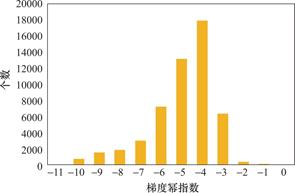
图3 梯度数值幂指数直方图
Fig.3 Power exponential histogram of gradient values
为此,本文设计使用一个参数来对量化表的梯度数值进行动态缩放,具体过程如算法(1)所示。其中,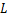 为梯度的幂指数张量,为统计每个梯度幂指数取值的个数序列,为每个梯度幂指数可取数值所组成的序列,为梯度分布统计函数,用以返回梯度幂指数取值的个数序列和梯度幂指数可取数值序列,
为梯度的幂指数张量,为统计每个梯度幂指数取值的个数序列,为每个梯度幂指数可取数值所组成的序列,为梯度分布统计函数,用以返回梯度幂指数取值的个数序列和梯度幂指数可取数值序列,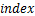 是梯度幂指数个数最多的下标,为梯度序列中出现概率最高的幂指数,用以对梯度数值进行缩放。
是梯度幂指数个数最多的下标,为梯度序列中出现概率最高的幂指数,用以对梯度数值进行缩放。
算法1:量化表更新方法
Input:量化表
Output:更新后的量化表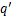
Begin
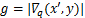
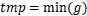
if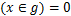
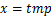
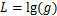
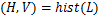
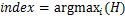
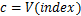
if(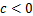 )
)
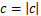
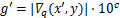
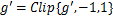
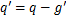
End
实现过程,表述如下。首先,AdvDrop+计算求得量化表梯度数值张量的绝对值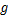 ,若张量中梯度为0,则对其进行修正,将其赋值为量化表梯度数值中最小的值,接着采用log函数计算梯度幂指数,判断梯度数值的分布范围,再用函数计算出现概率最高的梯度幂指数,得到参数。当为负数时,说明梯度数值过小,对进行取反操作,对梯度数值进行一定的放大。最后对量化表梯度数值进行缩放,更新量化表。在对梯度缩放的同时也要防止量化表的梯度范围过大或者过小。因此,本文遵循AdvDrop,更新后的量化表梯度需要被限制在一定的范围内。
,若张量中梯度为0,则对其进行修正,将其赋值为量化表梯度数值中最小的值,接着采用log函数计算梯度幂指数,判断梯度数值的分布范围,再用函数计算出现概率最高的梯度幂指数,得到参数。当为负数时,说明梯度数值过小,对进行取反操作,对梯度数值进行一定的放大。最后对量化表梯度数值进行缩放,更新量化表。在对梯度缩放的同时也要防止量化表的梯度范围过大或者过小。因此,本文遵循AdvDrop,更新后的量化表梯度需要被限制在一定的范围内。
4 实验
本章节概述了实验设置,评估了AdvDrop和AdvDrop+在不同的条件限制下的对抗攻击性能与视觉感知质量。此外,本章节还对比了AdvDrop和AdvDrop+攻击不同目标模型的成功率以及使用不同数据集生成的对抗样本的攻击效果,最后对实验结果进行了分析。
4.1 实验设置
4.1.1 数据集
本文分别采用ImageNet、CIFAR-10和MNIST中各1000张正确分类的图像用于测试。
4.1.2 目标模型
为评估对抗攻击的有效性,本文选用6个目标模型进行实验,分别是ResNet50、ResNet101、VGG16、AlexNet、Inception-v3和GoogleNet。
4.1.3 比较方法
本文使用攻击成功率作为评估对抗攻击的有效性指标。在目标攻击中,攻击成功率定义为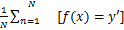 。
。
此外,对抗攻击的成功率只能在一定程度上表明对抗样本的质量,为了更好地评估对抗样本的攻击性能还需要其他的评估指标。故本文遵循AdvDrop算法,选用感知图像块相似度(Learned Perceptual Image Patch Similarity,LPIPS)以衡量生成对抗样本与原始样本之间的差异,lpips的数值越小,说明对抗样本与原始样本越相似,反之,差异越大。
4.1.4 实验参数
本文将验证集的每个图像经过变换,图像尺寸为长224、宽224。同时考虑到计算成本和图像的感知质量,在实验过程中将图像进行分块处理,图像的块大小为8,图像的批处理大小为20。量化过程中的量化初始值为5。实验采用Adam优化器,学习率重置为0.01,采用交叉熵损失函数作为对抗损失函数。以上设置均遵循AdvDrop算法。
4.2 实验分析
在AdvDrop算法中,攻击性能主要与攻击过程中的的迭代次数和量化表的扰动预算,即量化范围有关。故实验过程中,本文首先设置量化表的量化范围为5,比较不同迭代次数下算法的攻击性能。算法改进前后的攻击成功率如表2所示。实验结果表明,当量化表的量化距离范数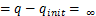 ,即扰动预算固定时,随着攻击迭代次数的增加,AdvDrop 的攻击成功率逐渐增大,lpips也相应变大,图像丢失的信息增多。与此同时,AdvDrop+的攻击成功率和lpips也逐渐增大。对比表2中的数据,可以看出在量化表扰动预算和迭代次数一致的情况下,AdvDrop+与AdvDrop相比,AdvDrop+攻击成功率有非常明显的提高,且lpips相差无几。换言之,AdvDrop+在提高攻击成功率的同时,还保持着和AdvDrop基本一致的视觉感知质量。由以上结果可知,在图像失真几近相同的情况下,AdvDrop+有着比AdvDrop更好的攻击性能。
,即扰动预算固定时,随着攻击迭代次数的增加,AdvDrop 的攻击成功率逐渐增大,lpips也相应变大,图像丢失的信息增多。与此同时,AdvDrop+的攻击成功率和lpips也逐渐增大。对比表2中的数据,可以看出在量化表扰动预算和迭代次数一致的情况下,AdvDrop+与AdvDrop相比,AdvDrop+攻击成功率有非常明显的提高,且lpips相差无几。换言之,AdvDrop+在提高攻击成功率的同时,还保持着和AdvDrop基本一致的视觉感知质量。由以上结果可知,在图像失真几近相同的情况下,AdvDrop+有着比AdvDrop更好的攻击性能。
此外,若固定攻击的迭代次数为50,逐渐增加量化表的扰动预算,改进前后算法的性能对比结果如表3所示。实验结果表明,当攻击迭代次数相同但量化范围较小时,AdvDrop+与AdvDrop相比,仍然有更高的攻击成功率,且lpips几乎一致,保证人眼不可感知。然而,随着量化范围的逐渐增大,AdvDrop+算法与AdvDrop算法的攻击效果会逐渐趋同。趋同的原因在于DNNs能感知而人类肉眼不可察觉的信息丢失得越多,DNNs输出错误分类结果的可能性越大,因此当图像丢失的信息量达到某一个阈值时,AdvDrop和AdvDrop+生成的对抗样本都能产生强对抗性,算法的攻击性能都会越来越好,逐渐趋向相同的值。总体而言,AdvDrop+相较于AdvDrop在低迭代次数和低量化扰动预算下都表现出显著提高的攻击成功率,并且保持了几乎相同的图像视觉感知质量,使人眼不可感知。
表4中的结果进一步比较了AdvDrop+与AdvDrop对不同目标模型的攻击成功率,实验参数包括量化范围为10,攻击迭代次数为120。通过观察表4的数据,可以明显看出AdvDrop+在攻击不同目标模型时表现出更高的成功率,而这一趋势在攻击任意一个模型时都得到了体现。这表明相对于AdvDrop,AdvDrop+在对抗攻击性能方面具有显著的优势。针对对抗攻击的迁移性问题,AdvDrop+在以ResNet50为源模型,攻击其他ResNet模型时表现出了非常高的成功率。然而,反之情况并不相同。在相同的参数设置下,AdvDrop+攻击其他模型的成功率并不高。在这种情况下,AdvDrop+可以通过调整参数来提高攻击成功率。这一发现提示AdvDrop+需要对不同目标模型采用个性化的参数设置,以更有效地优化攻击效果。
表5则比较了AdvDrop与AdvDrop+使用不同数据集生成的对抗样本的攻击成功率。在ImageNet数据集上,使用量化范围为10和攻击迭代次数为120时,二者取得了显著的高攻击成功率。这是因为ImageNet数据集包含大量类别和复杂图像,导致目标模型对细小的扰动更为敏感,因此在相对较短的攻击迭代次数内就能够生成有效的对抗样本。然而,在CIFAR-10数据集上,为了实现近90%的攻击成功率,AdvDrop与AdvDrop+需要调整参数,包括将量化范围增加至20,并增加攻击迭代次数至400。这是因为CIFAR-10数据集相对较小,需要更大的量化范围和更多的攻击迭代次数来产生有效的对抗样本。相比之下,MNIST数据集上的攻击成功率仅为25%左右,即便在较大的量化范围50和更多的攻击迭代次数500下。这是因为MNIST数据集较为简单,需要更大的量化范围和更多的攻击迭代次数才能使攻击变得有效。总体而言,不同数据集和模型的特性导致对抗攻击参数的不同敏感性,这在实验设计中需要特别考虑。
表2 迭代次数与成功率
Table 1 Iterations and success rate
|
迭代次数
|
ADVDROP
|
LPIPS
|
ADVDROP +
|
LPIPS
|
|
50
|
10.5%
|
0.0019
|
25.1%
|
0.0019
|
|
70
|
12.2%
|
0.0019
|
26.8%
|
0.0020
|
|
90
|
12.5%
|
0.0020
|
29.8%
|
0.0020
|
|
120
|
15.7%
|
0.0020
|
34.1%
|
0.0020
|
|
200
|
18.2%
|
0.0020
|
38.1%
|
0.0021
|
|
400
|
18.5%
|
0.0021
|
42.5%
|
0.0022
|
表3 量化范围与成功率
Table 3 Quantization range and success rate
|
量化范围
|
ADVDROP
|
LPIPS
|
ADVDROP+
|
LPIPS
|
|
[5,8]
|
1.6%
|
0.0015
|
5.2%
|
0.0016
|
|
[5,10]
|
10.5%
|
0.0019
|
25.1%
|
0.0019
|
|
[5,15]
|
65.6%
|
0.0028
|
70.6%
|
0.0028
|
|
[5,20]
|
90.5%
|
0.0037
|
90.6%
|
0.0039
|
|
[5,25]
|
96.3%
|
0.0043
|
96.3%
|
0.0044
|
|
[5,30]
|
98.1%
|
0.0055
|
98.5%
|
0.0057
|
表4 攻击不同模型的成功率
Table 4 Success rate of attacking different models
|
方法
|
RESNET50
|
RESNET101
|
VGG16
|
ALEXNET
|
INCEPTION-V3
|
GOOGLENET
|
|
ADVDROP
|
94.7%
|
93.7%
|
92.0%
|
35.6%
|
41.4%
|
83.2%
|
|
ADVDROP +
|
95.6%
|
94.4%
|
92.6%
|
40.1%
|
42.7%
|
83.4%
|
表5 不同数据集生成对抗样本的攻击成功率
Table 5 Attack success rate of adversarial examples generated from different datasets
|
数据集
|
IMAGENET
|
CIFAR-10
|
MNIST
|
|
ADVDROP
|
94.7%
|
89.2%
|
25.0%
|
|
ADVDROP +
|
95.6%
|
90.3%
|
27.1%
|
5 总结与展望
本篇文章提出了改进的AdvDrop算法——AdvDrop+。不同于AdvDrop在量化过程中未考虑到量化表不同的梯度数值对于对抗效果的不同影响,AdvDrop+对量化表的梯度数值进行分析并以此为根据更新量化表。该方法首先计算量化表梯度数值张量,并对0数值进行修正,接着计算梯度张量幂指数,判断梯度分布范围,再有选择地缩放梯度,防止造成在迭代过程中梯度对抗修改不足或者梯度修正步长过大的问题。该算法显著提高了对抗攻击的成功率,同时保证人眼无法察觉丢失的图像细节。
此外,本文对未来的工作提出了一些想法,可以有以下改进:
(1)AdvDrop+在DCT域进行变换,未来的工作可以尝试在小波域不同分解的层次上进行降信息操作;
(2)AdvDrop+在尺寸为8 × 8的DCT域上进行变换,未来的工作可以考虑在不同的DCT域尺寸上进行变换;
(3)未来的工作中可以考虑根据图像内容的复杂度,采用基于四叉树的图像分割技术,选择不同的DCT域变换的块尺寸,重点对图像细节比较多的DCT域进行更加精细化的降信息操作。
利益冲突: 作者声明没有利益冲突。
[①] *通讯作者 Corresponding author:李施旻,shimin.li@nuaa.edu.cn
收稿日期:2023-11-07; 录用日期:2023-11-23; 发表日期:2024-06-28
参考文献(References)
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[2] Zeng M, Wang Y, Luo Y. Dirichlet latent variable hierarchical recurrent encoder-decoder in dialogue generation [C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing( EMNLP-IJCNLP). 2019: 1267-1272.
https://doi.org/10.18653/v1/D19-1124.
[3] Spencer M, Eickholt J, Cheng J. A Deep Learning Network Approach to ab Initio Protein Secondary Structure Prediction[J]. IEEE/ACM transactions on computational biology and bioinformatics, 2014, 12(1): 103-112.
https://doi.org/10.1109/TCBB.2014.2343960.
[4] Liao Y, Vakanski A, Xian M. A Deep Learning Framework for Assessing Physical Rehabilitation Exercises[J]. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 2020, 28(2): 468-477.
https://doi.org/10.1109/TNSRE.2020.2966249.
[5] Dahl G E, Yu D, Deng L, et al. Context-dependent Pretrained Deep Neural Networks for Large-vocabulary Speech Recognition[J]. IEEE Transactions on audio, speech, and language processing, 2011, 20(1): 30-42.
https://doi.org/10.1109/TASL.2011.2134090.
[6] Chan W, Jaitly N, Le Q, et al. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition[C]//2016 IEEE international conference on acoustics, speech and signal processing(ICASSP). IEEE, 2016: 4960-4964.
https://doi.org/10.1109/ICASSP.2016.7472621.
[7] Shokri R, Stronati M, Song C, et al. Membership inference attacks against machine learning models[C]//2017 IEEE symposium on security and privacy(SP). IEEE, 2017: 3-18.
https://doi.org/10.1109/SP.2017.41.
[8] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv e-prints, 2013: arXiv: 1312. 6199.
https://doi.org/10.48550/arXiv.1312.6199.
[9] Bojarski M, Del Testa D, Dworakowski D, et al. End-toend learning for self-driving cars[J]. arXiv e-prints, 2016: arXiv: 1604. 07316.
https://doi.org/10.48550/arXiv.1604.07316.
[10] Lopes A T, De Aguiar E, De Souza A F, et al. Facial expression recognition with convolutional neural networks: coping with few data and the training sample order[J]. Pattern recognition, 2017, 61(0031-3203): 610-628.
https://doi.org/10.1016/j.patcog.2016.07.026.t.
[11] Grosse K, Papernot N, Manoharan P, et al. Adversarial examples for malware detection[C]//European symposium on research in computer security. Springer, Cham, 2017: 62-79.
https://doi.org/10.1007/978-3-319-66399-9_4.
[12] Cubuk E D, Zoph B, Mane D, et al. Autoaugment: learning augmentation strategies from data[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 113-123.
[13] 潘文雯, 王新宇, 宋明黎, 等. 对抗样本生成技术综述 [J]. 软件学报, 2020, 31(1): 67-81.
https://doi.org/10.13328/j.cnki.jos.005884.
[14] Khan M E, Khan F. A comparative study of white box, black box and grey box testing techniques[J]. International Journal of Advanced Computer Science and Applications, 2012, 3(6): 1-15.
https://doi.org/10.14569/IJACSA.2012.030603.
[15] Papernot N, McDaniel P, Goodfellow I, et al. Practical black-box attacks against machine learning[C]//Proc of the 2017 ACM on Asia conference on computer and communi-cations security. 2017: 506-519.
https://doi.org/10.1145/3052973.3053009.
[16] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv e-prints, 2014: arXiv: 1412. 6572.
https://doi.org/10.48550/arXiv.1412.6572.
[17] Fawzi A, Fawzi O, Frossard P. Fundamental limits on adversarial robustness[C]//Proc. ICML, Workshop on Deep Learning. 2015: 55.
[18] Gilmer J, Metz L, Faghri F, et al. Adversarial spheres[J]. arXiv e-prints, 2018: arXiv: 1801. 02774.
https://doi.org/10.48550/arXiv.1801.02774.
[19] Schmidt L, Santurkar S, Tsipras D, et al. Adversarially robust generalization requires more data[C]//Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018: 5019-5031.
[20] Ilyas A, Santurkar S, Tsipras D, et al. Adversarial examples are not bugs, they are features[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019: 125-136.
[21] Duan R, Chen Y, Niu D, et al. AdvDrop: Adversarial attack to DNNs by dropping information[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 7506-7515.
[22] Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world[M]//Artificial Intelligence Safety and Security. Chapman and Hall/CRC, 2018: 99-112.
[23] Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[J]. arXiv preprint arXiv: 1706. 06083, 2017.
https://doi.org/10.48550/arXiv.1706.06083.
[24] Papernot N, McDaniel P, Jha S, et al. The limitations of deep learning in adversarial settings[C]//2016 IEEE European symposium on security and privacy(EuroS&P). IEEE, 2016: 372-387.
https://doi.org/10.1109/EuroSP.2016.36.
[25] Moosavi-Dezfooli S M, Fawzi A, Frossard P. Deepfool: a simple and accurate method to fool deep neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2574-2582.
[26] Carlini N, Wagner D. Towards evaluating the robustness of neural networks[C]//2017 IEEE symposium on security and privacy(SP). IEEE, 2017: 39-57.
https://doi.org/10.1109/SP.2017.49.
An Adversarial Example Method Based on Dropping Information to Improve Attack Capability
LI Shimin*, ZHANG Yongming
(College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing 211100, China)
Abstract: At present, deep neural network has been widely used in many research fields. However, with the in-depth research on artificial intelligence research, it is found that artificial intelligence technology based on deep neural networks bringsconvenience coming with potential security risks. For example, an attacker may misguide the image classification model to output a wrong result with high confidence by adding slight perturbations to a clean image via the adversarial example method. Compared with the previous methods of adding additional information to the images to generate adversarial examples, Ranjie Duan et al. proposed the AdvDrop algorithm. In this algorithm, adversarial examples are generated by deleting the existing information of the images, which is realized by adjusting the quantization step. However, in the quantization process, the AdvDrop algorithm does not consider the different effects of different gradient values of the quantization table on the adversarial effect. In this regard, AdvDrop+ is proposed, that is, in each iteration, the quantization tables are updated according to the gradient numerical values scaled with a factor. To find the proper scaling factor, we find the gradient value of the highest frequency in the gradient histogram and compute its logarithm and the final result is the scaling factor. The experiments show that AdvDrop+ has better attack performance than AdvDrop under the setting of target attack with nearly the same image distortion. At the same time, AdvDrop+ retains the characteristic of AdvDrop, which can drop information.
Keywords: Neural networks, adversarial example, image example, dropping information
DOI: 10.48014/ccsr.20231107001
Citation: LI Shimin and ZHANG Yongming. An adversarial example method based on dropping information to improve attack capability[J]. Chinese Computer Sciences Review, 2024, 2(2): 14-23.
